A multiway tree can have more than one value per node. They are written as m-way trees where the m means the order of the tree. A multiway tree can have m-1 values per node and m children. Although, not every node needs to have m-1 values or m children.
B-Trees
A B-tree is a specialized M-way tree that is widely used for disk access. A B tree of order m can have a maximum of m–1 keys and m pointers to its sub-trees. It was developed in the year 1972 by Bayer and McCreight .

Haui [CC-BY-SA 3.0]
A B-tree is designed to store sorted data and allows search, insertion, and deletion operations to be performed in logarithmic running time.
Property of B-Trees
- All the leaf nodes must be at the same level.
- All nodes except root must have at least [m/2]-1 keys and maximum of m-1 keys.
- A non-leaf node with n-1 keys must have n number of children.
- All the key values within a node must be in Ascending Order.
- All internal nodes must have at least m/2 children.
- If the root node is a non leaf node, then it must have at least two children.
There are several variations of the B-Tree that are popularly being used:
1. B+ Trees
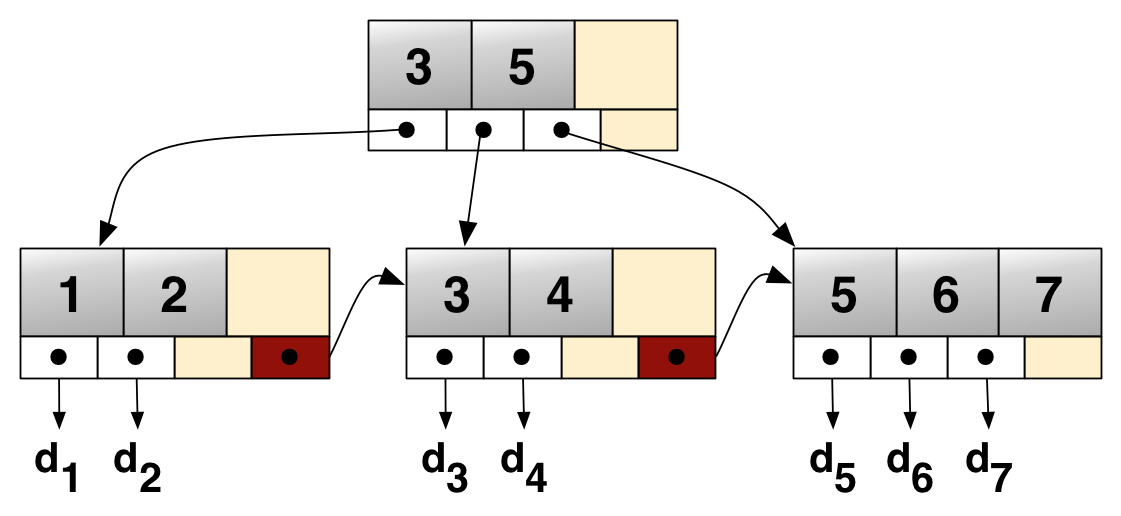
Grundprinzip [CC BY 3.0]
A B+ tree can be viewed as a B-tree, but each node contains only keys (not key-value pairs), and it stores all the records at the leaf level of the tree instead.
It has two parts – the first part is the index set that constitutes the interior nodes and the second part is the sequence set that constitutes the leaves.
The linked leaves make it possible for the keys to be accessed sequentially in addition to accessing them directly. This is an advantage over a normal B+ tree as it allows for efficient retrieval of data.
Uses of B+ Tree
File Indexing: The efficient retrieval of a B+ Tree allows for use in file indexing operations. The high number of pointers to the child nodes in a node help to reduce the number of I/O operations required to find an element in the tree, making it ideal for data retrieval where I/O operations take time.
Property of B+ Trees
- Inserting a record requires O(log n) operations
- Finding a record requires O(log n) operations.
- Removing a (previously located) record requires O(log n) operations.
- Performing a range query with k elements occurring within the range requires O(log n + k)operations.
Insertion
The procedure to insert a key is similar to a B-Tree. When the leaf node is split into two nodes, a copy of the low-order key from the rightmost node is promoted from the separator key value in the parent node. The new node also must be inserted in the linked list of the sequence set.
Deletion
The deletion of a key is easier in a B-tree. When a key value is deleted from a leaf, there is no need to delete that key from the index set of the key. The key value still searches to the proper leaves.
2. B* Tree
The B* Tree’s main idea was to reduce the overhead involved in insertion or deletions. It also has better search performance.
Each node in a B* Tree is2/3rd full instead of half full. This is different from a normal B Tree where each node is at least half full.
Visualisations
- B-Trees Visualisation: Excellent visualization from cs.usfca.edu
- B+ Trees Visualisation: Excellent visualization from cs.usfca.edu
Videos
- An Introduction to B-Trees | Fullstack Academy
- B Trees and B+ Trees. How they are useful in Databases | Abdul Bari Excellent explanation and about its uses
- 2-3 Trees and B-Trees | MIT OCW Full class from MIT